01 — Introduction
What is Clickbait?
Clickbait refers to headlines engineered to provoke curiosity and compel clicks — often through sensationalism, vague promises, or emotional manipulation — while the actual content fails to deliver on the implied value.
"You Won't Believe What This Celebrity Did Next!" is the archetypal clickbait — designed to trigger, not to inform.
Detecting clickbait automatically is critical for:
-
→
Improving news feed quality and user trust
-
→
Fighting misinformation and low-quality journalism
-
→
Training media literacy at scale via AI tools
02 — Objective
Project Goals
-
01
Build a binary text classifier that identifies news headlines as clickbait or non-clickbait with high accuracy using classical ML techniques.
-
02
Compare the performance of Logistic Regression, Naive Bayes, and SVM on TF-IDF-vectorised headline features.
-
03
Evaluate each model using Accuracy, Precision, Recall, and F1-score, then validate on real-world custom headlines.
03 — Dataset
Kaggle Clickbait Dataset
Source
Kaggle
Total Headlines
32,000
Clickbait (label=1)
15,999
Non-Clickbait (label=0)
16,001
Train / Test Split
80% / 20%
Features
headline, label
Dataset URL
kaggle.com/datasets/amananandrai/clickbait-dataset
The dataset is perfectly balanced (~50/50 split), eliminating class-imbalance bias. Headlines were sourced from BuzzFeed (clickbait) and mainstream news outlets (non-clickbait).
04 — Methodology
NLP Pipeline
STEP 01
📥
Data Ingestion
Download dataset via Kaggle API; load into Pandas DataFrame and inspect class balance.
Kaggle · Pandas
STEP 02
🧹
Text Cleaning
Lowercase, strip URLs and punctuation, remove extra whitespace using regex.
re · string
STEP 03
✂️
Train/Test Split
Stratified 80/20 split ensures label proportions are preserved in both sets.
sklearn
STEP 04
🔢
TF-IDF Vectorisation
Top 5,000 unigram+bigram features weighted by term frequency–inverse document frequency.
TfidfVectorizer
STEP 05
🤖
Model Training
Logistic Regression and Naive Bayes trained; SVM included for comparison.
LR · NB · SVM
STEP 06
📊
Evaluation
Accuracy, Precision, Recall, F1-score and Confusion Matrix compared across models.
sklearn.metrics
05 — Models
Classifiers Used
Learns a weight per TF-IDF token. Words like "shocking" and "you won't believe" get high weights — directly interpretable. Outputs probability scores, not just binary labels.
Best for interpretability & probability outputs
Assumes feature independence; computes P(clickbait | words). Highly efficient on sparse TF-IDF matrices. Achieved slightly higher overall accuracy.
Finds maximum-margin hyperplane in high-dimensional TF-IDF space. Robust to overfitting in sparse text; strong baseline comparator.
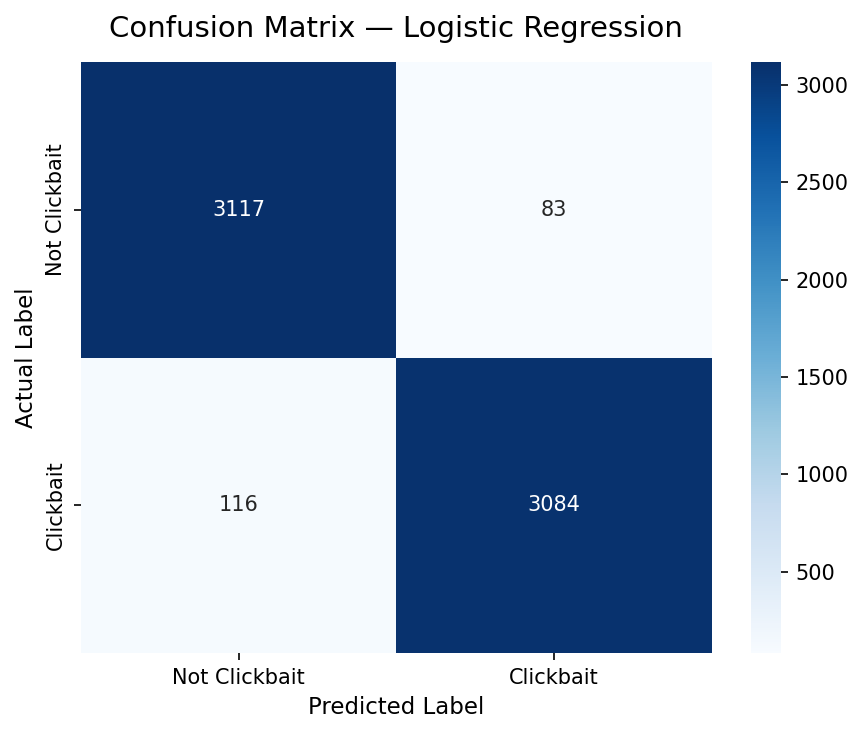
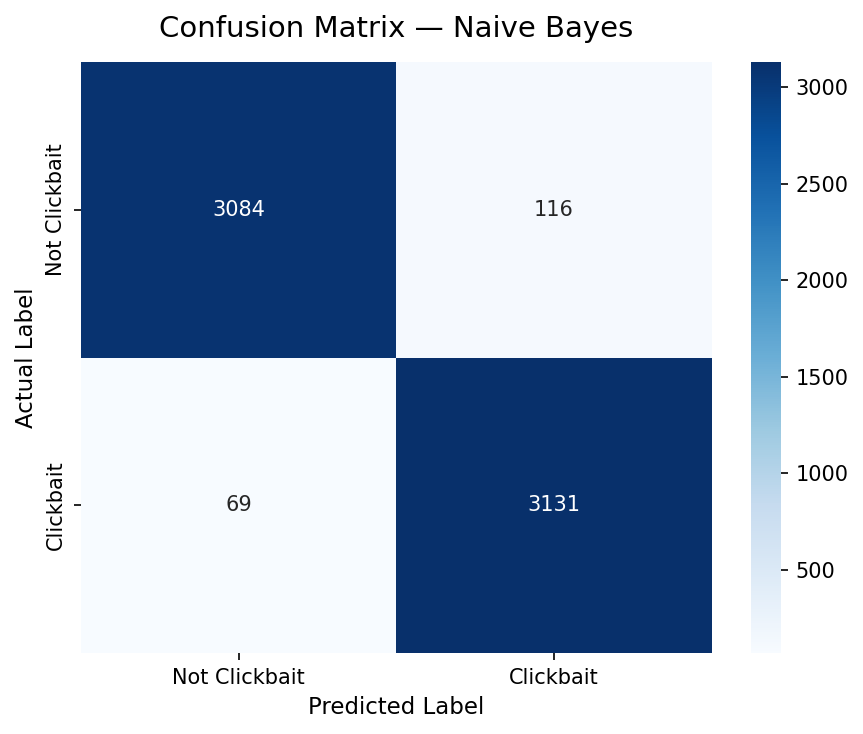
06 — Results & Evaluation
Model Performance
| Metric |
Logistic Regression |
Naive Bayes ▲ Best |
| Accuracy |
|
|
| Precision |
|
|
| Recall |
|
|
| F1-Score |
|
|
Live Predictions (LR Model)
NOT CLICKBAIT 85.4% Scientists discover new Alzheimer's treatment
CLICKBAIT 92.6% You won't believe what this celebrity did next!
NOT CLICKBAIT 96.9% Government announces new budget for 2025
CLICKBAIT 97.4% 10 shocking things doctors don't want you to know
07 — Conclusion
Key Takeaways
🎯
High-Accuracy Results
Both models exceeded 96% accuracy on 6,400 test headlines, validating that TF-IDF + classical ML is highly effective for headline-level clickbait detection.
🏆
Naive Bayes Wins Narrowly
Naive Bayes (97.11%) edged Logistic Regression (96.89%) across all four metrics, with notably fewer false negatives. Making it more reliable at catching real clickbait.